Applying Archived Operations Data in Transportation Planning: A Primer
3. CONQUERING THE CHALLENGES OF USING ARCHIVED OPERATIONS DATA
Data, tools, and domain expertise are the three components required to effectively use archived operations data in planning. Without these three basic components, users of archived data will be unable to derive the meaningful insights that help to make informed decisions that intelligently move an agency forward (Figure 4).
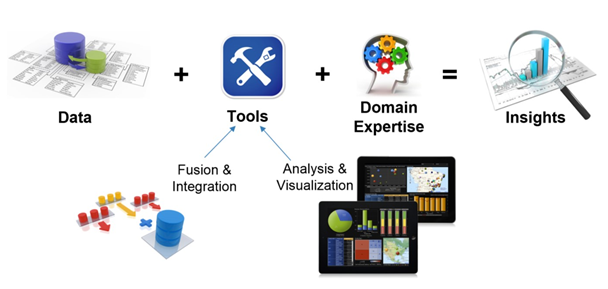 Figure 4. Diagram. Components of an effective archived operations data archive.
Source: University of Maryland CATT Laboratory
Figure 4. Diagram. Components of an effective archived operations data archive.
Source: University of Maryland CATT Laboratory.
Data. Chapter 1 provided an overview of the various types of archived operations data. Data captured by an agency or third-party may include speeds, volumes, accidents, freight movements, transit schedule and ridership, agency assets, and others. However, simply knowing that this data
exists and is in an archive someplace is not sufficient; stakeholder buy-in and understanding how to access the data also are needed.
Tools. Often overlooked, the tools that are available to agency staff are the most critical element in making use of archived operations data. These can include tools that fuse "siloed" data from disparate sources, the tools that fill in gaps ("missing data"), and those that identify or screen outliers. Other important tools support analytics and visualization that help the agencies "see" into the data—asking questions, identifying issues, deriving meaning from the data, and communicating those insights to others.
Domain expertise. With the right tools and the right data, anyone can review a data set and start to ask questions, but to ask the right questions, to interpret the resulting analysis, and to otherwise act on the information in the archive, domain expertise is needed. Domain experts include transportation professionals with specific technical skills in areas such as traffic operations, transportation planning, or statistical analysis.
There is a mixture of technical and political challenges within an institution associated with creating an effective archive. All can be overcome with varying degrees of effort. The remainder of this chapter focuses on some of the more prevalent institutional challenges associated with the data, tools, and domain expertise of an operations archive.
Institutional Challenges
A common misconception about using archived operations data is that the technical challenges associated with the collection, fusion, and management of the data, along with the development of tools, are the greatest hurdles. In reality, these technical challenges are almost always easily solvable by qualified technical personnel. However, the institutional challenges (e.g., political, ideological, etc.) can create significant issues that delay and/or prevent operations data from being leveraged fully. The extent to which each of these issues may exist in each agency will vary greatly.
Technology policy. Many agencies have strict guidelines on what technologies can and cannot be used within its own enterprise. For example, some agencies use only Microsoft products and platforms, such as .NET and MS SQL; whereas, other agencies forbid open-source software for fear of being unable to find available support for a product or that misuse of the open-source technologies could lead to litigation.
Resource constraints. An agency may want to build and maintain their archive internally, but quickly find that they lack the capacity to do so. This may not necessarily be a lack of skills, but rather, a lack of skilled individuals. An agency who takes on a significant development effort with only one or two superior coders or minimal information technology (IT) support may find its program at a standstill if the specialized personnel leave the agency or are otherwise committed to other agency projects.
Storage and processing capacity. Technical barriers are common to agencies that are building archives in-house. Certain archives, especially those from connected vehicles or probe-based data sets, can grow at a surprising rate. The Florida Department of Transportation (FDOT), for example, collects data from approximately 5,000 speed/volume sensors. This sensor network produces the equivalent of 3.6 million data points every day and over 1.3 billion records each year. Sensor networks like the one FDOT uses produce only a fraction of the data generated by probe data sources. Using FDOT again as an example, the data the agency purchases from a third-party probe data provider produces nearly 34,000 records every single minute. That translates to 48.9 million records per day or 17.8 billion records per year. Due to State procurement and hiring policies, very few departments of transportation (DOTs) have dedicated and responsive IT teams that can plan out, install, and configure expensive hardware or cloud services to accommodate these massive archives for long periods of time.
Tools and accessibility. Even when hardware can be purchased and installed, developing the appropriate analytics software and databases that make the data easily accessible to end users can be a significant hurdle for agencies. For an agency to build successful tools independently, a healthy mixture of software engineers, architects, user interface and user experience design specialists, developers, and project managers is necessary. The tools will need to be maintained over time; therefore, complete documentation and staff that can be called upon over the course of many years to keep the tools up-to-date are needed. Because of the high barrier to entry and upkeep costs, many agencies are now choosing to either purchase existing tools, or leverage tools that other agencies or universities have already paid to develop. This effectively creates a pooled fund approach to software development and maintenance. This approach is becoming easier to use for those agencies who are unaccustomed to purchasing services and for those who have historically not adopted tools and products that have not been invented in-house or even in-State.
Networking bandwidth. Though less common, agencies may have issues with networking and bandwidth capacity. Large data sets that stream from various sources will need to be compiled and streamed to others. The ability to send large sets of data from field devices or to and from third-party providers can be difficult with existing infrastructure.
Security concerns. Working with agency security boards or committees can be another challenge that often seems insurmountable. Getting the appropriate permission to set up online data access or to deploy specialized software, for example, can range from 1 month to several years, or even be denied if there is not an advocate.
If present, most technical issues are solvable if there is an internal advocate. Network capacity can be expanded at relatively low costs. Other IT and hardware procurement issues can be bypassed by outsourcing to contractors or through the purchase of software-as-a-service or IT-as-a-service.
 Figure 5. Photo. Technician.
Source: Thinkstock/Dynamic rank.
Figure 5. Photo. Technician.
Source: Thinkstock/Dynamic rank.
Internal resistance. Internal resistance may develop when: (1) trying to convince the owner of the data or archive to share it with others, (2) trying to convince those who have not traditionally relied on operations data to trust its quality, and (3) trying to convince potential users of the value of the operations data compared to traditional (or currently used) data sets.
- Sharing—internal conflict over the ownership and control of data, information, and the capability that comes with it is not uncommon. It is important to understand the various motivations for wanting data versus the motivations for providing data. It is the responsibility of the owner and administrator of a particular data set to keep that data safe and secure (i.e., to be the steward). What motivation is there for releasing that data to larger audiences? At best, the data steward may be recognized for his or her efforts to maintain the data or get a verbal "thanks." More likely, however, the data steward is fearful that, in releasing the data to others, the data may become scrutinized excessively (or inappropriately) by outside groups. Thus, the data steward becomes bombarded with questions. If the data is incorrect, or even misinterpreted, or if there is a security breach or something is damaged, his or her job could be jeopardized. It can seem like a lose-lose situation for the steward. For the majority of agencies, there is little to no apparent benefit to the steward to make the data more widely available.
- Trusting—for those who have yet to make use of archived operations data or those who have biases towards other types of data, deciding to look at operations data can be difficult. There is an old school of thought that goes: "Data collected for planners is of higher quality than that for the operations folks. Those operations people only care about in-the-moment conditions, and do not take the same quality control initiatives that planners take on their data." This is essentially a lack of trust in the quality of someone else’s data, which is not perceived as being collected for the same purposes or need as someone else. This lack-of-trust issue is so pervasive that it is not uncommon to find more than one set of detectors at a single location: one for the planners, one for operations personnel, and a third for the private sector or other agency. Each group thinks the other group is not doing a good enough job in quality control (QC) or maintenance on their device. However, getting past the trust issue can be easier than many other challenges. A quick verification and validation process performed on the data can show where issues exist. Many third-party archive applications (e.g., Regional Integrated Transportation Information System (RITIS) and Iteris Performance Measurement System (iPeMS) have data quality checking modules that can quickly identify issues, patterns, and causality in just a few minutes. These tools can verify or deny the existence of an issue, and help to encourage fixing the problem. From an economic standpoint, it is often much more cost-effective to pool the resources of several departments to fix the quality of the operations data set rather than to continue to expend resources to collect data multiple times at the same location.
- Valuing—when existing processes are in place for collecting, processing, and cleansing non-operations data, proving that the operations data has enough value to warrant switching to use it (or augmenting existing data with the operations data) can seem daunting. If a business unit in an organization already has a well-formed process for collecting, processing, and managing data from another source, then what is the impetus for trying something different? Often, it is simply a matter of better marketing and demonstrating the benefits of enhanced or augmented data by the operations groups. More and more, operations data sets, especially those from probes, are proving to be highly reliable, of finer granularity, and to have greater spatial coverage than traditional planning data sets. The fact that they are continually collected also is a positive aspect of these data sets—even though that does present additional data management burdens. Ultimately, an internal advocate is needed to clarify the benefits and quality of the data and to make the case for either switching to it or augmenting existing data with it.
Additional arguments have been used to overcome issues with sharing, trusting, and valuing operations data with varying degrees of success. There is the sensible argument, which debates the philosophical and ethical arguments of sharing data and pooling resources. There is the legal justification, which attempts to leverage interagency agreements or executive orders to change behavior. There is the funding argument, which attempts to pay an agency or business unit to switch their data collection and sharing practices in an effort to get past the "the cost is too great" excuse. There is the "shame" argument, which attempts to show how everyone else in the organization is sharing data and leveraging resources, thus isolating those individuals who are resisting. The problem with these tactics is that they do not address the "fear factor" that many individuals have about changing their behavior and sharing their data with others.
By showcasing the tools and capabilities that will be made available when the operations data is archived and accessible, others will want to make use of the data and share it as well.
There is the "make a friend" tactic, which leverages personal connections to try to instill change. This tactic often is successful as it is communications-based. However, if only the leadership within an organization is convinced, but the individuals who daily work with the data are unconvinced, then as soon as the ally within the organization gets promoted, retires, or otherwise leaves the organization, the resistance returns.
Ultimately, every manager and analyst in every agency has questions that need answers and is looking for insights into their own data. If these managers and data stewards can be shown the power of certain visualization and analytics tools that they will gain access to as part of the archive, they usually will understand the value of the data, realize that it is worth the supposed risk of using the data, and make it available to others through sharing. This is the "build it and they will come" approach. By showcasing the tools and capabilities that will be made available when the operations data is archived and accessible, others will want to make use of the data and share it with others. Tools can be built in-house with some risk, as described later. However, existing tools and applications developed by third parties or other agencies also can be showcased. Leveraging existing tools to showcase the power of operations data often is the quickest, cheapest, and least risky approach to demonstrating capabilities, securing stakeholder buy-in, and getting a process up and running in as little time as possible.
Challenges in Changing Planning Methods and Products
The use of archived operations data may require planners to adjust their technical methods and modify their products. Historically, travel demand forecasting (TDF) models have been used not only to forecast future performance but also to estimate current performance where performance measurement data were lacking. With archived data, the use of models to "measure" current performance is no longer necessary. Therefore, products that formerly relied on models to derive current conditions now have to be converted to use measured data. Switching from models to data for these applications requires planners to develop a strategy. Some of the issues that need to be addressed include:
- Coverage. Will the archived data cover the roadways of interest? If not, how will the non-covered roadways be handled?
- Example: Congestion management process (CMP). An agency only has archived operations data of speeds and volumes for area freeways, yet the current CMP monitors signalized arterials and collectors. The agency may decide to purchase travel time data from a commercial vendor.
- Reporting period. How frequently does the archived data need to be obtained: monthly, quarterly, or annually?
- Maintaining continuity in trends. If a trend line exists from the models, how will the switch to archived data affect it?
- Example: CMP. An agency has been producing a biennial mobility performance report that is based on applying its TDF model. It is changing to vendor-supplied travel time data. A test revealed that, for the current year, the performance measures developed with the data are significantly different from the modeled measures, resulting in a discontinuity in trends. A possible solution is to use the results from the current year tests to adjust the previous years" performance. This can be done by noting the percent difference between modeled and measured data for the current year to develop adjustment factors by time of day and highway type.
- Definitions of performance measures. Will the measures developed with archived data represent the same underlying phenomenon as the modeled measures?
- Example: Delay estimates using TDF models. Delay computations require three inputs: a reference (usually free flow) speed, actual speed, and the volume of vehicles exposed to a speed. TDF models are used to develop these estimates; all three delay inputs are available at the link level; therefore, delay is computed for each link and summed. If vendor supplied travel times are used, there are numerous sources of incompatibility: the vendor and TDF networks usually will not align; reference speeds may be calculated differently; and, most significantly, companion volumes to the travel time estimates do not exist. Likewise, the estimates of speeds for air quality models would benefit from using both travel time and volume data so that the proper weighting can be applied.
The most desirable solution is to conflate the TDF and vendor travel time networks. This ensures that delay estimates are made on the same spatial basis and makes the volumes from the TDF model available for use with the travel time measurements. Note that conflation is a complicated process that requires both networks to use a common geolocation referencing system (e.g., latitude/longitude). If the TDF network does not have "points of contact" (either attributes or shared line work), the vendor network may be conflated to other traffic count databases that do provide that information, such as the Highway Performance Monitoring System (HPMS).
- Acceptance of new performance measures. How will the introduction of new performance measures enabled by archived data fit into current products?
- Example: Including travel time reliability in the long-range transportation plan (LRTP). Improving travel time reliability is increasingly appearing as a stated goal of LRTPs. When this is the case, methods for monitoring and forecasting should be in place. Reliability performance can be measured directly with archived data, but what role does archived data play in forecasting reliability? Recent experience suggests there are at least two ways to use archived data. First, some metropolitan planning organizations (MPOs) have used archived data to reformulate the volume-delay functions used in their TDF models. By using continuously collected travel time data, the effects of the factors that cause unreliable travel (e.g., weather, work zones, incidents, or demand fluctuations) are accounted for in the revised functions. Second, archived data can be used to develop relationships between model-produced average travel time or speed values and reliability metrics. Both of these applications are discussed in more detail in Chapter 5.