| |
This chapter provides guidance on the identification, collection, and preparation of the data sets needed to develop a microsimulation model for a specific project analysis, and the data needed to evaluate the calibration and fidelity of the model to real-world conditions present in the project analysis study area. There are agency-specific techniques and guidance documents that focus on data collection, which should be used to support project-specific needs.
A selection of general guides on the collection of traffic data includes:
These sources should be consulted regarding appropriate data collection methods (they are not all-inclusive on the subject of data collection). The discussion in this chapter focuses on data requirements, potential data sources, and the proper preparation of data for use in microsimulation analysis.
If the amount of available data does not adequately support the project objectives and scope identified in task 1, then the project team should return to task 1 and redefine the objectives and scope so that they will be sufficiently supported by the available data.
The precise input data required by a microsimulation model will vary by software and the specific modeling application as defined by the study objectives and scope. Most microsimulation analytical studies will require the following types of input data:11
In addition to the above basic input data, microsimulation models also require data on vehicle and driver characteristics (vehicle length, maximum acceleration rate, driver aggressiveness, etc.). Because these data can be difficult to measure in the field, it is often supplied with the software in the form of various default values.
Each microsimulation model will also require various control parameters that specify how the model conducts the simulation. The user's guide for the specific simulation software should be consulted for a complete list of input requirements. The discussion below describes only the most basic data requirements shared by the majority of microsimulation model software.
The basic geometric data required by most models consist of the number of lanes, length, and free-flow speed.12 For intersections, the necessary geometric data may also include the designated turn lanes and their vehicle storage lengths. These data can usually be obtained from construction drawings, field surveys, geographical information system (GIS) files, or aerial photographs.
Control data consist of the locations of traffic control devices and signal-timing settings.13 These data can best be obtained from the files of the agencies operating the traffic controls or from field inspection.
The basic travel demand data required for most models consist of entry volumes (traffic entering the study area) and turning movements at intersections within the study area. Some models require one or more vehicular O-D tables, which enable the modeling of route diversions. Procedures exist in many demand modeling software and some microsimulation software for estimating O-D tables from traffic counts.
Traffic counts should be conducted at key locations within the microsimulation model study area for the duration of the proposed simulation analytical period. The counts should ideally be aggregated to no longer than 15-minute (min) time periods; however, alternative aggregations can be used if dictated by circumstances.14
If congestion is present at a count location (or upstream of it), care should be taken to ensure that the count measures demand and not capacity. The count period should ideally start before the onset of congestion and end after the dissipation of all congestion to ensure that all queued demand is eventually included in the count.
The counts should be conducted simultaneously if resources permit so that all count information is consistent with a single simulation period. Often, resources do not permit this for the larger simulation areas, so the analyst must establish one or more control stations where a continuous count is maintained over the length of the data collection period. The analyst then uses the control station counts to adjust the counts collected over several days into a single consistent set of counts representative of a single typical day within the study area.
For some simulation software, the counts must be converted into an estimate of existing O-D trip patterns. Other software programs can work with either turning-movement counts or an O-D table. An O-D table is required if it is desirable to model route choice shifts within the microsimulation model.
Local metropolitan planning organization (MPO) travel demand models can provide O-D data; however, these data sets are generally limited to the nearest decennial census year and the zone system is usually too macroscopic for microsimulation. The analyst must usually estimate the existing O-D table from the MPO O-D data in combination with other data sources, such as traffic counts. This process will probably require consideration of O-D pattern changes resulting from the time of day, especially for simulations that cover an extended period of time throughout the day.
A license plate matching survey is the most accurate method for measuring existing O-D data. The analyst establishes checkpoints within and on the periphery of the study area and notes the license plate numbers of all vehicles passing by each checkpoint. A matching program is then used to determine how many vehicles traveled between each pair of checkpoints. However, license plate surveys can be quite expensive. For this reason, the estimation of the O-D table from traffic counts is often selected.15
The vehicle characteristics typically include vehicle mix, vehicle dimensions, and vehicle performance characteristics (maximum acceleration, etc.).16
Vehicle Mix: The vehicle mix is defined by the analyst, often in terms of the percentage of total vehicles generated in the O-D process. Typical vehicle types in the vehicle mix might be passenger cars, single-unit trucks, semi-trailer trucks, and buses.
Default percentages are usually included in most software programs; however, the vehicle mix is highly localized and national default values will rarely be valid for specific locations. For example, the percentage of trucks in the vehicle mix can vary from a low of 2 percent on urban streets during rush hour to a high of 40 percent of daily weekday traffic on an intercity interstate freeway.
It is recommended that the analyst obtain one or more vehicle classification studies for the study area for the time period being analyzed. Vehicle classification studies can often be obtained from nearby truck weigh station locations.
Vehicle Dimensions and Performance: The analyst should attempt to obtain the vehicle fleet data (vehicle mix, dimensions, and performance) from the local State DOT or air quality management agency. National data can be obtained from the Motor and Equipment Manufacturers Association (MEMA), various car manufacturers, FHWA, and the U.S. Environmental Protection Agency (EPA). In the absence of data from these sources, the analyst may use the defaults shown in Table 2.
Vehicle Type |
Length (ft) |
Maximum Speed (mi/h) |
Maximum Acceleration (ft/s2) |
Maximum Deceleration (ft/s2) |
Jerk |
|---|---|---|---|---|---|
Passenger car |
14 |
75 |
10 |
15 |
7 |
Single-unit truck |
35 |
75 |
5 |
15 |
7 |
Semi-trailer truck |
53 |
67 |
3 |
15 |
7 |
Double-bottom trailer truck |
64 |
61 |
2 |
15 |
7 |
Bus |
40 |
65 |
5 |
15 |
7 |
Sources: CORSIM and SimTraffic™ technical documentation
Notes:
Maximum Speed: Maximum sustained speed on level grade in miles per hour
(mi/h)
Maximum Acceleration: Maximum acceleration rate in feet per second squared
(ft/s2) when starting from zero speed
Maximum Deceleration: Maximum braking rate in ft/s2 (vehicles can actually
stop faster than this; however, this is a mean comfort-based maximum)
Jerk: Maximum rate of change in acceleration rates in feet per second cubed
(ft/s3)
Metric Conversion: 1 ft = 0.305 m, 1 mi/h = 1.61 km/h, 1 ft/s2 = 0.305 m/s2, 1 ft/s3
= 0.305 m/s3
Calibration data consist of measures of capacity, traffic counts, and measures of system performance such as travel times, speeds, delays, and queues. Capacities can be gathered independently of the traffic counts (except during adverse weather or lighting conditions); however, travel times, speeds, delays, and queue lengths must be gathered simultaneously with the traffic counts to be useful in calibrating the model.17 If there are one or more continuous counting stations in the study area, it may be possible to adjust the count data to match the conditions present when the calibration data were collected; however, this introduces the potential for additional error in the calibration data and weakens the strength of the conclusions that can be drawn from the model calibration task.
Finally, the analyst should verify that the documented signal-timing plans coincide with those operating in the field. This will confirm any modifications resulting from a signal retiming program.
It is extremely valuable to observe existing operations in the field during the time period being simulated. Simple visual inspection can identify behavior not apparent in counts and floating car runs. Video images may be useful; however, they may not focus on the upstream conditions causing the observed behavior, which is why a field visit during peak conditions is always important. A field inspection is also valuable for aiding the modeler in identifying potential errors in data collection.
The best source of point-to-point travel time data is "floating car runs." In this method, one or more vehicles are driven the length of the facility several times during the analytical period and the mean travel time is computed. The number of vehicle runs required to establish a mean travel time within a 95-percent confidence level depends on the variability of the travel times measured in the field. Free-flow conditions may require as few as three runs to establish a reliable mean travel time. Congested conditions may require 10 or more runs.
The minimum number of floating car runs needed to determine the mean travel time within a desired 95-percent confidence interval depends on the width of the interval that is acceptable to the analyst. If the analyst wishes to calibrate the model to a very tight tolerance, then a very small interval will be desirable and a large number of floating car runs will be required. The analyst might aim for a confidence interval of ± 10 percent of the mean travel time. Thus, if the mean travel time were 10 min, the target 95-percent confidence interval would be 2 min. The number of required floating car runs is obtained from equation 1:
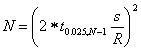 (Equation 1)
(Equation 1)
where:
R = 95-percent confidence interval for the true mean
t0.025,N-1 = Student's t-statistic for two-sided error of 2.5 percent (totals 5 percent) with N-1 degrees of freedom (for four runs, t = 3.2; for six runs, t = 2.6; for 10 runs, t = 2.3)
(Note: There is one less degree of freedom than car runs when looking up the appropriate value of t in the statistical tables.)
s = standard deviation of the floating car runs
N = number of required floating car runs
For example, if the floating car runs showed a standard deviation of 1.0 min, a minimum of seven floating car runs would be required to achieve a target 95-percent confidence interval of 2.0 min (± 1.0 min) for the mean travel time.
The analyst is advised that the standard deviation is unknown prior to runs being conducted. In addition, the standard deviation is typically higher under more congested conditions.
Traffic management centers (TMCs) are a good source of simultaneous speed and flow data for urban freeways. Loop detectors, though, may be subject to failure, so the data must be reviewed carefully to avoid extraneous data points. Loop detectors are typically spaced 0.5 to 0.8 km (0.3 to 0.5 mi) apart and their detection range is limited to 3.7 meters (m) (12 feet (ft)). Under congested conditions, much can happen between detectors, so the mean speeds produced by the loop detectors cannot be relied on to give system travel times under congested conditions.
The loop-measured free-flow speeds may be reliable for computing facility travel times under uncongested conditions; however, care should be taken when using these data. Many locations have only single-loop detectors in each lane, so the free-flow speed must be estimated from an assumed mean vehicle length. The assumed mean vehicle length may be automatically calibrated by the TMC; however, this calibration requires some method of identifying which data points represent free-flow speed, which data points do not, and which ones are aberrations. The decision process involves some uncertainty. In addition, the mix of trucks and cars in the traffic stream varies by time of day, thus the same mean vehicle length cannot be used throughout the day. Overall, loop-estimated/-measured free-flow speeds should be treated with a certain amount of caution. They are precise enough for identifying the onset of congestion; however, they may not be an accurate measure of speed.
Capacity and saturation flow data are particularly valuable calibration data since they determine when the system goes from uncongested to congested conditions:
Delay can be computed from floating car runs or from delay studies at individual intersections. Floating car runs can provide satisfactory estimates of delay along the freeway mainline; however, they are usually too expensive to make all of the necessary additional runs to measure all of the ramp delays. Floating cars are somewhat biased estimators of intersection delay on surface streets since they reflect only those vehicles traveling a particular path through the network. For an arterial street with coordinated signal timing, the floating cars running the length of the arterial will measure delay only for the through movement with favorable progression. Other vehicles on the arterial will experience much greater delays. This problem can be overcome by running the floating cars on different paths; however, the cost may be prohibitive.
Comprehensive measures of intersection delay can be obtained from surveys of stopped delay on the approaches to an intersection (see the HCM for the procedure). The number of stopped cars on an approach is counted at regular intervals, such as every 30 s. The number of stopped cars multiplied by the counting interval (30 s) gives the total stopped delay. Dividing the total stopped delay by the total number of vehicles that crossed the stop line (a separate count) during the survey period gives the mean stopped delay per vehicle. The stopped delay can be converted to the control delay using the procedure in Appendix A of chapter 16 in the HCM.
Data preparation consists of review, error checking, and the reduction of the data collected in the field. Data reduction is already well covered in other manuals on data collection. This section consequently focuses on review and error checking of the data. The following checks of the data should be made during the data preparation step:
Inevitably, there will be traffic counts at two or more nearby adjacent locations that do not match. This may be a result of counting errors, counting on different days (counts typically vary by 10 percent or more on a daily basis), major traffic sources (or sinks) between the two locations, or queuing between the two locations. In the case of a freeway, a discrepancy between the total traffic entering the freeway and the total exiting it may be caused by storage or discharge of some of the vehicles in growing or shrinking queues on the freeway.
The analyst must review the counts and determine (based on local knowledge and field observations) the probable causes of the discrepancies. Counting errors and counts made on different days are treated differently than counting differences caused by midblock sources/sinks or midblock queuing.
Discrepancies in the counts resulting from counting errors or counts made on different days must be reconciled before proceeding to the model development task. Inconsistent counts make error checking and model calibration much more difficult. Differing counts for the same location should be normalized or averaged assuming that they are reasonable. This is especially true for entry volumes into the model network. Intersection turning volumes should be expressed as percentages based on an average of the counts observed for that location. This will greatly assist with calibrating the model later.
Differences in counts caused by midblock sources (such as a parking lot) need not be reconciled; however, they must be dealt with by coding midblock sources and sinks in the simulation model during the model development task.
Differences in entering and exiting counts that are caused by queuing in between the two count locations suggest that the analyst should extend the count period to ensure that all demand is included in both counts.
Accurate vehicle classification counts and accurate travel speeds can also affect the traffic volumes. Trucks and other large vehicles and inaccurate speeds can skew the volume counts.
The same ramp metering example problem discussed in chapter 1.0 is continued here. Now the task is to identify, gather, and prepare the data for the study area and the afternoon peak-hour analytical period.
Road Geometry: Aerial photographs, construction drawings, and field inspections are used to obtain the lengths and the number of lanes for each section of the freeway, ramps, and surface streets. Turn lanes and pocket lengths are determined for each intersection. Transition lengths for lane drops and additions are determined. Lane widths are measured if they are not standard widths. Horizontal curvature and curb return radii are determined if the selected software tool is sensitive to these features of the road and freeway design. Free-flow speeds are estimated based on the posted speed limits for the freeway and the surface streets.
Traffic Controls: Existing signal settings were obtained from the agencies' records and verified in the field. The controllers at the interchange ramp terminals are all fixed-time, having a cycle length of 90 s. The signals along Green Bay Avenue are traffic-actuated.
Demands: Field measurements of traffic volumes on the freeway mainline and ramps, and turning-movement counts at each intersection were conducted for a 2-h period during the afternoon peak period (4:00 to 6:00 p.m.). The peak hour was determined to be between 5:00 and 6:00 p.m., and the highest 15-min volumes occurred between 5:30 and 5:45 p.m.
Vehicle Characteristics: The default vehicle mix and characteristics provided with the microsimulation software were used in this analysis.21
Calibration Data: The model will be calibrated against estimates of capacity and traffic counts, and the system performance will be assessed against travel time data.
Saturation flows for protected movements at traffic signals were estimated using the HCM 2000 methodology and verified through field observations at a few approaches with long queues.22
Capacity values for basic freeway segments were estimated using the HCM 2000 procedures.23
The traffic count data have already been discussed.
The system performance calibration data were obtained at the same time as the traffic counts, which consisted of travel times obtained from floating car runs, delays at traffic signals, and speeds on the freeway.
Data Preparation: The input data were reviewed by the analyst for consistency and accuracy prior to data entry. The turning, ramp, and freeway mainline counts were reconciled by the analyst to produce a set of consistent counts for the entire study area. After completion of the reconciliation, all volumes discharged from upstream locations are equal to the volumes arriving at the downstream location. Based on local knowledge of the area, the analyst determined that midblock sources were not required for the surface streets in the study area.
Table of Contents | List of Tables | List of Figures | Top of Section | Previous Section | Next Section | HOME