Scoping and Conducting Data-Driven 21st Century Transportation System AnalysesModule 3. Preparing Data to Conduct a Transportation AnalysisModule 3 describes a key element of the data-driven analytic project scoping cycle. Diverse data are integrated while ensuring temporal and geographic consistency so that the analysis team is ready to move forward to conduct and document analytics projects. Figure 24 highlights this module within the 21st Century Analytic Project Scoping Process. During the scoping process, the team identified the performance measures that reveal underlying transportation system dynamics. Data needs are then derived to calculate these measures and provide the context for their variation (e.g., variation in demand, incident patterns, and weather impacts). Figure 24. Diagram. Data preparation within the 21st Century analytic project scoping process.
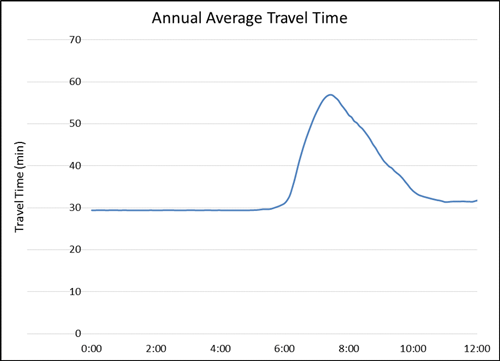
(Source: Federal Highway Administration.) As shown in Figure 24, this module provides practical advice on assessing data gaps and needs, preparing and collecting data, and identifying operational conditions. In Module 2, the key performance measures and the analysis tool to solve the transportation problem were selected. Based on the selections, the required data to conduct the analysis is also identified. These data could be any key data whose absence would impair the ability to conduct the project. These key data may be collected by others and need only be obtained and integrated. In other cases, if targeted primary data collection is required, a data collection plan is developed and existing data are assessed and integrated. In this module, an analyst verifies the consistency and the quality of the data available and outlines the data collection plan to fill the gap between needs and availability. Depending on the nature and scope of the project, the analyst may review the available data to identify a representative set of operational conditions. Assessing Data GapsThis section describes the types of data gaps and process for assessing these gaps to help an analyst determine if a new or additional data collection is needed to use resources as efficiently as possible. Concentrating on identified key measures, the analyst captures and assembles data that create, inform, or provide the context to understand these measures. In general, it is better to have a small set of measures and deep insight into their patterns and variations rather than a large number of measures with limited insight on their dynamics or interrelation. A data analysis also identifies the strengths and weaknesses of specific data (and data sources). For example, are the data overly smoothed or are they up-to date? If the data is not always accurate, analysis may reveal the conditions under which the data are more or less reliable. Data gaps identification and potential primary data collection are pre-procurement activities, followed by operational conditions analysis, if required. Performance measures and analysis data requirements have been identified in Module 2, so Module 3 provides a more detailed assessment of data needs versus availability. The assessment result helps procure a properly resourced and focused analytical project in Module 4. Data Sources and LimitationsAvailable data come from different sources, such as traffic data from sensors, incident data from enforcement or emergency response agencies, and weather data from weather data collection centers. Before integrating data from multiple databases, an analyst must understand how the data are collected and the source of the data from the existing studies in order to identify data gaps and needs. When preparing traffic data to conduct a microscopic simulation for AM peak period, a data analyst first identifies the AM peak hours based on the historical traffic data or previous studies because different locations or transportation modes have different peak periods. A simulation time horizon may last longer than the identified AM peaks when the projected performance for benefits last longer. If the existing data source cannot serve this need, a data analyst documents the gap. This gap may be resolved through an additional data collection activity or by integrating other data. Data resolution (e.g., 5 min., 15 min., or hourly) is another key component in this exercise. A higher data resolution is needed to evaluate an intersection traffic signal control performance compared to an annual freeway corridor performance study. The analyst must determine whether the data resolution is sufficient for the project, depending on the nature of the problem and the scope of the project. Figure 25 shows an example of using existing travel-time data to virtually identify the AM peak hours (from 6:00 a.m. to 10:00 a.m.). Figure 25. Chart. Annual average corridor travel time profile on Seattle I-405 south bound in 2012.
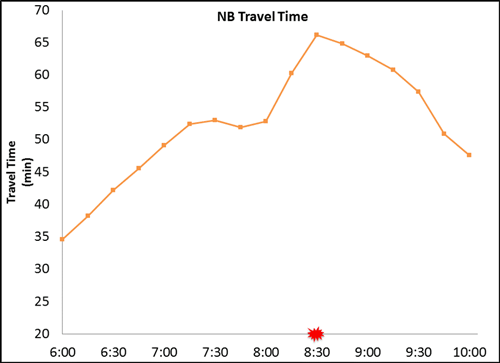
(Source: Federal Highway Administration.) Temporal and Spatial ConsistencyConsistency is one of the major concerns of using existing data. When data come from different sources and are collected in different time periods and different locations, are the data still useful and valid for an analytical project? To be able to use existing data, what kind of additional data collection is needed to adjust existing data? Detailed weather data may be available for the specific geographic locations (e.g., nearby airports); to be able to use this detailed weather data to describe conditions away from these locations on the surface transportation system, the analyst may choose to test weather conditions mid-way between these locations can be reliably predicted by combining airport observations by collecting a small sample of relevant weather and road surface data. Not all inconsistency issues can be overcome easily through supplementary estimation by assessing congestion impacts due to incidents. Figure 26 provides a one-day travel time profile and an incident identified from the incident database within the same time horizon. The travel time profile shows a typical pattern through 7:15 AM with a dramatic increase around 8:30 AM due to an incident blocking a travel lane. This relationship between incident location and travel-time dynamics cannot be identified when using the traffic and incident data from different years—only contemporaneous data reveals the relationships. Figure 26. Chart. One-day travel time profile with an associated incident.
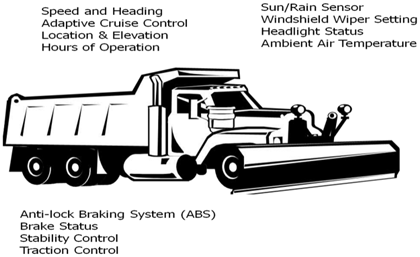
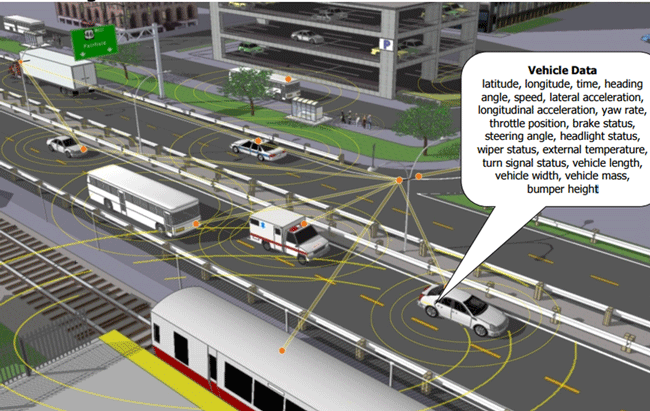
(Source: Federal Highway Administration.) Emerging Trends in Operational DataTraditionally, vehicle count is available through either a traffic count survey (manual or tube count) or traffic detectors (loop or mounted detector). Travel time is estimated by speed data from detectors or by recording vehicle trajectory from survey vehicles. With the 21st Century innovation technology, different types of datasets are available to provide more detailed and potentially more accurate information, such as probe data and connected vehicle data. Although the market penetration rate is not high enough to replace traditional data, this subset of data can be used for data verification or adjustment. Another set of data is crowd-sourced data from private sectors or individuals. Before using this set of data, the analyst must verify accuracy and legitimacy. This data set could be used as a supplement from a trusted source. One of the great opportunities for the 21st Century data analyst is to incorporate these emerging datasets into the analytic project development process. Some examples of emerging data sources are listed in the following subsections. First-Generation Probe DataProbe data are obtained by wireless communications with Global Positioning System (GPS)-equipped vehicles or mobile devices moving in the transportation system and post-processed to characterize current and historical patterns of congestion. These first generation systems primarily leverage vehicle or device position and current speed from many participants, fused with historical data and other sources to create comprehensive travel time and congestion data products. Probe data providers. Some data providers collect trillions of bytes of information about vehicles on the roads from real-time anonymous mobile phones, connected cars, trucks, delivery vans, and other fleet vehicles equipped with GPS locator devices. The data collected is processed in real-time to provide historical, real-time traffic information, traffic forecasts, travel times, travel-time polygons, and traffic count to businesses and individuals. The capability of first-generation probe data product providers continues to grow in offerings and product detail. Probe data technology solutions. Different from generalized data providers, probe data technology solutions facilitate targeted collection of vehicle position and location data on specific routes passively detecting and re-identifying vehicles moving in the transportation system. Several technologies can be considered; traditional License Plate Recognition (LPR) is a technology used to count vehicles and estimate arterial travel time. Using existing closed-circuit television (CCTV), road-rule enforcement cameras, or ones specifically designed for the task, this approach applies optical character recognition on images to read vehicle registration plates. The application includes police forces, electronic toll collection on pay-per-use roads and cataloging the movements of traffic or individuals, such as path travel time and the origin-destination (O-D) matrix. Similarly, toll tag technologies and Bluetooth reader technologies can be used to match vehicles in one location that appear later in other parts of the network. These probe data are a readily available resource to the 21st Century data analyst and have some key features of interest to fill gaps or support travel time analyses, including continuous coverage over time, broad geographic coverage (beyond the facilities covered by fixed sensor deployments), and the ability to characterize travel times in multi-modal trip making. Connected Vehicle DataEfforts are under way to systematically augment position and speed data with other information. The U.S. Department of Transportation (USDOT), the Road Bureau of Ministry of Land, Infrastructure, Transport, and Tourism (MLIT) of Japan, and the European Union's European Commission Directorate General for Communications Networks, Content & Technology (DG CONNECT) established a Trilateral Probe Data Working Group to coordinate research efforts on the three high-priority applications of connected vehicle data that were selected for joint study: Traffic Management Measures Estimation, Dynamic Speed Harmonization, and Operational Maintenance Decision Support Systems. (Assessment Report of US-Japan-Europe Collaborative Research on Probe Data, International Probe Data Work Group Phase 2.) The Trilateral Probe Data Working Group defined probe data as data generated by vehicles about their current position, motion, and time stamp. Probe data includes additional data elements provided by vehicles that have added intelligence to detect traction information, brake status, hard braking, flat tire, activation of emergency lights, anti-lock brake status, air-bag deployment status, windshield wiper status, and so forth. Vehicle probe data may be generated by devices integrated with the vehicles' computers or nomadic devices brought into the vehicles. Integrated Mobile Observation (IMO) project is sponsored by the USDOT Road Weather Management Program (RWMP) to demonstrate how weather, road condition, and related vehicle data can be collected, transmitted, processed, and used for decision-making. Data are collected from both vehicles and external sensors, including atmospheric pressure, steering angle, anti-lock braking system, brake status, stability control system, traction control status, differential wheel speed, and emission data. Based on a partnership between USDOT and state DOTs, Figure 27 provides an example of probe data collected by snow plow trucks. Figure 27. Illustration. Example probe data from snow plow trucks.
(Source: U.S. Department of Transportation.) The USDOT initiated the connected vehicle research program to explore the potentially transformative capabilities of wireless technologies to make surface transportation safer, smarter, and greener and to enhance livability for Americans. The Society of Automotive Engineers (SAE) standard J2735, Dedicated Short Range Communications (DSRC) Message Set Dictionary defined the message sets, data frames, and data elements to produce interoperable DSRC applications. The message sets include a la carte message, basic safety message, emergency vehicle alert message, generic transfer message, a probe vehicle data message, and a common safety request message. (SAE J2735—Dedicated Short Range Communications (DSRC) Message Set Dictionary.) For example, connected vehicle safety applications rely on Basic Safety Message (BSM), which provides basic vehicle information, such as vehicle size, position, speed, heading acceleration, and brake system status. The vehicles equipped with connected vehicle onboard unit (OBU) will broadcast BSM. Figure 28 provides a graphical illustration of fully connected vehicle environment and the elements of vehicle data. Figure 28. Illustration. A fully connected vehicle environment.
(Source: U.S. Department of Transportation.) Data providers have begun to combine vehicle sensor data with other sources to provide new data feeds augmented with connected vehicle data. Vehicle temperature sensor and traction control data can be combined with traditional atmospheric weather information to give drivers advance warning of dangerous weather-related road conditions, keeping them safer on their route. Crowd-Sourced DataCrowdsourcing refers to "the practice of obtaining needed services, ideas, or content by soliciting contributions from a large group of people and especially from the online community rather than from traditional employees or suppliers." (Crowdsourcing definition.) One mobile navigation application relies on multiple forms of voluntary user input—crowdsourced data—to generate real-time traffic alerts, route suggestions, and estimated times of arrival. The USDOT Talking Technology and Transportation (T3) webinar provides some case studies of using crowdsourced data to enhance Transportation Management Center (TMC) operations. (T3 Webinar.) The nature and capability of crowdsourced data continues to develop. USDOT has sponsored the Enable Advanced Traveler Information System (ATIS 2.0) project to develop a smart phone application (shown in Figure 29) to collect traveler itinerary data and decision data, which can help refine near-term travel demand data. However, because these data rely on many individuals for content, one major concern of crowd-source data is the data quality and reliability. Before using it or committing to buy the data, a data analyst needs to do a quality check. Depending on the quality of the data, this type of data may only be used as supplemental data. Figure 29. Screenshot. Daily detail views for displaying predicted daily activities and trips from cell phone.
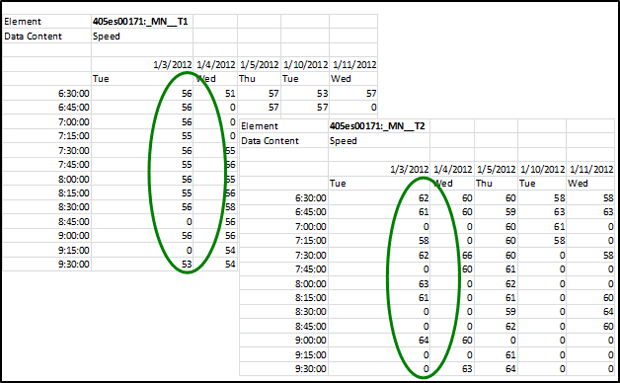
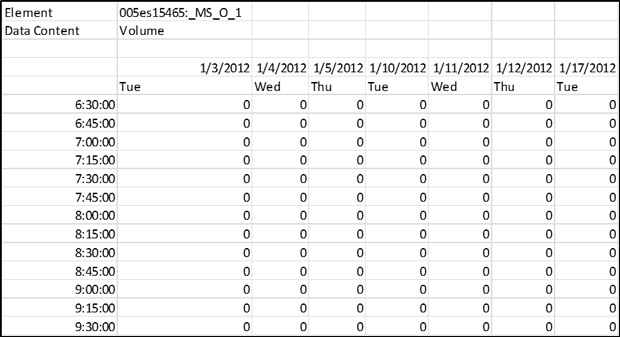
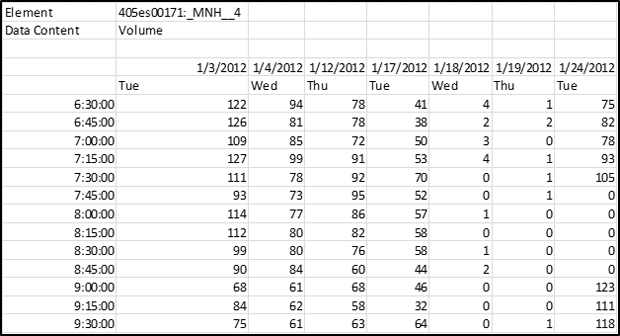
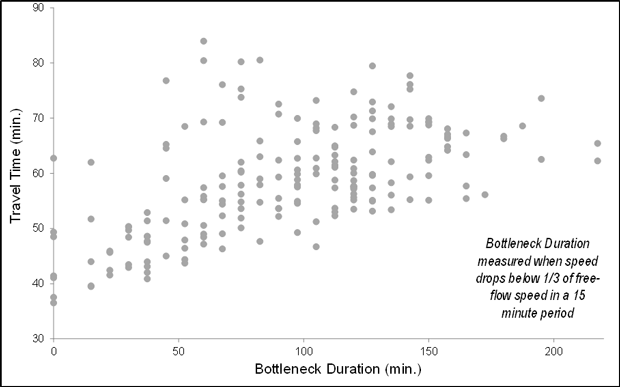
(Source: SmarTrAC/University of Minnesota, 2015.) Making Data Analytics-ReadyIn order to make the data ready and useful for conducting transportation analyses (Module 4), this section describes key components to consider when integrating data from multiple sources and controlling data quality. In some cases, if the needed data is not available, a data collection plan is prepared to describe the gap between available data and data needs, data resolution, how the data will be collected, and the final data format. Estimated cost is also included in the data collection plan. The analyst considers this process to be automatic if this is a recurrent effort. Data Integration from Multiple SourcesA data analyst needs to ensure that each data set refers to the same clock time when combining data sets. For example, a TMC has a system that collects data from roadway sensors automatically through wireless or fiber. Due to the delay of transferring data from sensors to the database or the collection frequency, a data analyst might need to reconcile the clock time so the combination of, for instance, traffic volume and signal timing information makes sense. Similar to temporal issues, geographically, a data analyst needs to integrate data sets in a proper way. One of the steps in developing an analysis plan in Traffic Analysis Toolbox Volume XIII: Integrated Corridor Management (ICM) Analysis, Modeling, and Simulation Guide (USDOT, ITS JPO, Traffic Analysis Toolbox Volume XIII: Integrated Corridor Management Analysis, Modeling, and Simulation Guide, May 5, 2012.)is to ensure data from multiple sources must also be for concurrent periods in order to neutralize seasonal and other travel pattern variances that can affect data. For example, data representing traffic conditions on the freeway during summer should not be compared with transit operating data collected during another time of the year. Cross validation is a way to ensure the proper temporal and geographical integration of different data sets. When integrating data, a data analyst determines if the volume matches speed at the same time, if the left turn vehicles come from the most left two lanes or if the volume or speed data reflects the impact of an incident occurred at the same time on the same location. During a field test of Multi-modal Intelligent Traffic Signal Systems (MMITSS) applications, University of Arizona found that MAP distortion caused the vehicle to send a "cancel priority request" to the system. The issue was solved by including other information to correct vehicle position. (USDOT, ITS JPO, Multi-Modal Intelligent Traffic Signal Systems (MMITSS) Impacts Assessment, FHWA-JPO-15-238, August 19, 2015.) When preparing data-related procurements, storage, licensing, and ownership issues are also critical. The analyst needs to figure out who owns the data and if the data can be used or manipulated. If an agency owns the data, does the agency have the right to release the license to the third party to conduct a procured project? If a database contains data from multiple sources, a data analyst needs to clarify the licensing and the ownership and how the data is stored and who has access to the database. Metadata is a set of data that describes and gives information about other data. Having a common metadata framework across all the systems and using common controlled vocabularies are the keys to ensure the consistency and reliability of metadata applied to the information and data assets. For example, the USDOT Data Capture Management (DCM) Program developed a Research Data Exchange (RDE) platform to share archived and real-time data from multiple sources and multiple modes to better support the needs of Intelligent Transportation Systems (ITS) researchers and developers while reducing costs and encouraging innovation. The USDOT published Metadata Guidelines for the RDE to be adopted by public- and private-sector data providers to increase usability of their data. (USDOT, FHWA, Metadata Guidelines for the Research Data Exchange, 2012.) Creation of metadata should be included in plans for the procurement of any data collection effort; otherwise, there is a risk that the data will be misinterpreted or abandoned as too arcane to support future analyses. A history of detector numbering should be included in the metadata so the analyst can link data sets from different years. Quality Control and Missing Data ImputationWhen conducting quality control of data or integrated data, a data analyst should avoid open-ended data quality control procedures and try to focus on the types of errors that are most likely to impact the results of the specific analytic project. The key notion is that there are many factors; since it isn't possible to control everything, the analyst focuses on controlling the factors that are important. In some cases, a data analyst needs to preserve outlier data in order to capture the time-variant traffic patterns (e.g., for a reliability analysis). Furthermore, certain types of analysis are more tolerant with respect to the error in the data, such as cluster analysis. The analyst needs to find a balance between setting quality control thresholds and preserving outliers while working around errors. An outlier is defined as an observation that lies an abnormal distance from other values in a random sample from a population. A variety of statistical tests are available to the analyst to identify and classify outlier data (including Scatter Plot, Box Plot, and Grubbs' Test). (Outlier definition.) A specific outlier may be the result of some sensor or processing error—or it could be an accurate reflection of variability in conditions. Before considering the possible elimination of these points from the data, the analyst should try to understand why they appeared and whether it is likely similar values will continue to appear. A key goal of the 21st Century data analyst is to preserve outliers not attributable to sensor and processing errors so that the full range of conditions can be characterized. Quality control is usually set as an automatic process that looks at individual elements of the data. For example, the speed should be greater than 0 and less than 99 mph. However, some problems in the data that are not revealed by an elemental level of quality control might be related to relationships among data (e.g., temporal and geographical inconsistencies). These inconsistencies (e.g., widely inconsistent input/output counts for adjacent traffic count sensors) can be problematic, even if the data has passed multiple elemental-level checks. In our inconsistent count example, the analyst cannot calibrate a time-dynamic model of the system with this set of data. If vehicles enter a tunnel, they have to exit the tunnel. They cannot just disappear in the tunnel. To effectively use analysts-in-the-loop is the key to successfully developing a need-driven targeted quality control process. If the data is used for calibration purposes, the quality control focus is on the important geographic and temporal components. Critical geographic components include the location of bottlenecks, and temporal components include the time of day when the congestion states transition in/around these bottlenecks. Once data is identified as missing during quality control, the analyst must decide whether to discard/disregard or impute missing data. Imputing data can be practical and realistic if the imputed data does not redefine or dominate the overall traffic pattern. Sometimes, the imputed data ends up introducing problems for calibration because the imputed data may introduce illogical relationships (e.g., unequal directional count data at a tunnel entrance and exit). When this happens, the modeled system cannot be calibrated. Another typical issue relates to the flagging of imputed data when passed from one step in the process to the next; one person assembles and imputes missing data, then hands off the data set to another person without pointing out which data has been imputed, causing calibration trouble because the comprehensive data set does not make sense anymore. Smoothing data (e.g., averaging values of certain time intervals) to minimize the impact of missing data is a common way to impute missing data. However, when the data are averaged several times during the integration and imputation process, the variation of data then is not significant. The analyst must avoid averaging data too much to capture the traffic patterns and impacts. Figure 30 through Figure 32 are detector data from the Seattle I-405 corridor. Figure 30 provides an example with speed data on Lane 1 (left table) and Lane 2 (right table). On January 3rd (the green circle), Lane 2 has more missing values than Lane 1. Without doing quality control, the analyst may choose to average the two values, resulting in inaccurate speeds at that roadway segment, causing trouble for later calibration. Cross validation and quality control are foundational elements to ensure data quality. Once missing data is identified, the analyst must determine whether to impute the missing data. Figure 31 shows an example of volume data at a detector station that all the values are missing and Figure 32 gives an example of volume data at another detector station where most values are available and a few are missing. The dataset in Figure 32 is the candidate for a data analyst to perform data imputation. Figure 33 illustrates an example of a travel time versus bottleneck duration graphic on the I-405 corridor. In this figure, the data with errors, such as zero travel time, are removed but the outliers, such as longer bottleneck duration are still preserved in the data set. Figure 30. Screenshot. Speed data on two lanes.
(Source: Federal Highway Administration.) Figure 31. Screenshot. All values are missing.
(Source: Federal Highway Administration.) Figure 32. Screenshot. Few values are missing.
(Source: Federal Highway Administration.) Figure 33. Chart. Natural variation in transportation system.
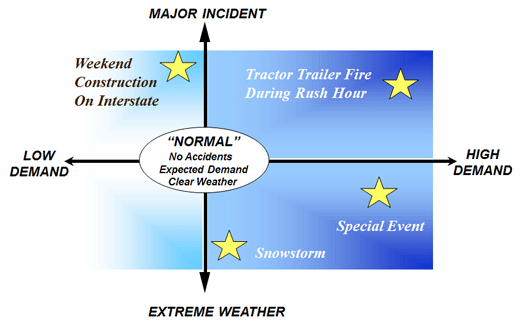
(Source: Federal Highway Administration.) Operational ConditionsThe availability of more continuous data improves the analyst's ability to characterize dynamic system performance. Analyses can be within a day (e.g., the rise and fall of travel times in a peak period) or over many days (e.g., the variation in travel times between a specific origin and destination departing at a specific time each day over a full year). Likewise, there is a corresponding pressure to assess more and more complex alternatives—intended to improve system performance—that are highly conditionally dependent (e.g., incident management and traveler information systems, road-weather technologies, and congestion pricing methods). The focus of this guide is on the characterization of time-dynamic system performance and the use of data-driven analytics to improve performance of transportation systems. In the past, when system data were scarce and potentially rife with errors, analysts tended to fall back on trying to describe a single, nominal "normal" operational condition derived by taking the average of many different attributes. In a 21st Century context, where data are more broadly available and contain far fewer errors, such an approach is obsolete. The 21st Century analyst instead uses a data-driven method to identify multiple distinct operational conditions to better characterize transportation system dynamics. This set of operational conditions is a more effective and useful basis for comparing alternatives and is a foundational element of any analytical effort aimed at improving system performance. Figure 34 illustrates one of the key challenges for analytical projects—to fully leverage and use available data sources in the design and execution of meaningful analyses that properly represent and test the competing investment alternatives. Figure 34. Diagram. Various operational conditions.
(Source: Federal Highway Administration.) A simulation tool, for example, is intended to predict or represent conditions under very specific conditions—conditions with well-defined travel demand, weather, and incident patterns. If input representing the average of many days is created for a simulation model, one likely outcome is the creation of a strange hybrid "normal" condition: multiple muted bottlenecks, unnaturally smooth travel times and speed profiles, with partial incidents and vague weather conditions (e.g., neither rainy nor clear). Such a day cannot serve as a useful differentiator of complex alternatives nor can it alone reveal anything regarding day-to-day travel-time reliability. To support the analyses of complex, condition-dependent alternatives or to conduct a reliability study using a simulation tool, a systematic data analysis to identify a practical set of representative operational conditions is required. Cluster Analysis. Cluster analysis is well-known and relatively simple statistical method that can be used to capture a variety of operation conditions that consider traffic, incident and weather impacts. (FHWA, Traffic Analysis Toolbox Volume III: Guidelines for Applying Traffic Microsimulation Modeling Software, FHWA-HOP-16-070, 2016.) Cluster analysis has been used in numerous research efforts over the last 20 years to identify various traffic patterns and characterize operational conditions. (Chen, Y., J. Kim, and H. S. Mahmassani. Pattern Recognition Using Clustering Algorithm for Scenario Definition in Traffic Simulation-Based Decision Support Systems. In Transportation Research Board 93rd Annual Meeting, 2014; and Azimi, M. and Y. Zhang. Categorizing freeway flow conditions by using clustering methods. Transportation Research Record, vol. 2173, pp.105-114, 2010.) Other statistical techniques with similar goals (e.g., set partitioning methods) can also be employed to derive a set of operational conditions from underlying data. (Buxi G. and M. Hansen. Generating day-of-operation probabilistic capacity scenarios from weather forecasts. Transportation Research Part C: Emerging Technologies, vol. 33, pp.153-166, 2013.) To conduct the underlying analyses to identify operational conditions, the analyst requires sufficient data. At a minimum, this includes time-variant traffic data (count and either speed or travel time data, incident data, and weather data). These data must be contemporaneous—all of the data must be from the same time period. The data required to characterize operational conditions is essentially the same data needed to create system performance profiles (Module 1). A minimum of 30 days of contemporaneous data is required to perform the simplest short-term analytic effort, generally associated with near-term operational analyses looking forward a few months. To compare alternatives expected to be in place for a year or more, an annual analysis based on as many days as possible (e.g., non-contemporaneous data removed) uniformly drawn from across a full calendar year is recommended. For analysts with good supporting data, it may be more practical to include all days from a calendar year or multiple years to characterize conditions rather than to randomly (or arbitrarily) reduce the sample set of data. The risk in random, arbitrary, or even systematic data reduction prior to analysis is that interesting outlier condition days (major incidents, bad weather, and special event days) may be underreported or unreported in a resulting analysis of these data. Unit of Observation. One typical stumbling block in preparing data for analysis is a failure to select an appropriate unit of observation for operational conditions analysis. Operational conditions are intended to describe the holistic state and performance of the transportation system in periods of intense dynamic change. For example, consider an analysis of alternatives to reduce peak period congestion on weekdays. Assume the data analyst has a contemporaneous set of data covering 200 weekdays over a calendar year. If the transportation system experiences two peak periods per day, each lasting roughly 6 hours with (relatively) uncongested conditions in the midday and overnight hours, choosing two peak periods (AM and PM) for separate analysis is recommended. The unit of observation for this analysis is based on an individual day, broken into the two relevant AM and PM portions. The analyst conducts one analysis on 200 AM peak periods to derive a practical set of representative AM peak operational conditions. The analyst conducts a second analysis on the 200 PM peak periods to derive a practical set of PM peak operational conditions. Operational conditions cannot be identified if the component elements (demand, incidents, and weather) are analyzed independently. First, the three component elements are not independent in reality. Poor weather suppresses travel demand and is correlated with higher incident rates and patterns. Second, such an independent analysis must eventually be merged together in order to conduct analyses—because analytic methods, particularly simulations, require the representation of a specific day, not a combination of days. The 21st Century analyst allows the dependencies among attributes of operational conditions to emerge from the data analysis. Selecting attributes. Individual detector speed and count data, or single incident reports, or weather station temperature readings by themselves in raw form are not suitable as attributes to attach to the peak period unit of observation for cluster analysis. Each peak period should be characterized using a set of normalized attributes (see Traffic Analysis Toolbox Volume III) that describe the nature of the travel demand, incident number, intensity and pattern, and weather conditions. Travel time and bottleneck throughput attributes. Two of the more typical attributes used in the characterization of operational conditions are travel times and bottleneck throughput rates. In each case, we are interested in the dynamics of these measures under congestion—how they rise and fall over time each day or peak period. The attribute of travel time for a route should reflect the travel time considering time of trip start from the origin and each intermediate node in the route, rather than an instantaneous addition of travel time from all links on the route at a specific time. This array of dynamic travel times can be used (when normalized) to characterize the timing and intensity of congestion on a route in the period. Note that several routes will likely be a part of a system characterization. Likewise, the flow rates at recurrent bottleneck locations is a critical determiner of system performance and the dynamics at these locations are critical for both calibration and system characterization. Bottleneck throughput tends to rise to some maximum, decline as the bottleneck becomes congested, then recover. The onset and dissipation times are keys to understanding the total system dynamics, as well as understanding analytical model calibration. Enumerative or attribute stratification approaches. Enumerating or stratifying all the possible combinations of conditions is not recommended; such an approach is both impractical and unnecessary. A typical approach seen in the design of many analytical studies is to take each of the possible attributes of the individual day or peak period, characterize these attributes, and then create a large n-dimensional grid of all the possible combinations. This approach has several major weaknesses. First, the approach quickly becomes impractical. Consider an analyst who without a cluster analysis, arbitrarily defines four travel demand patterns (e.g., low, medium-low, medium-high, high), eight incident patterns, and five weather conditions (clear, light rain, rain, fog, snow/ice). This results in 4 x 8 x 5 = 160 potential operational conditions, each of which will require data to characterize and an accompanying analytical representation for calibration. This is an extensive and largely unnecessary expenditure of effort. Consider that a full year of weekday operations results in roughly 200 actual days. The stratification effort has reduced the complexity of the analysis by only 40 runs (or 20%) versus a pure enumerative approach. Even more telling is that if the 200 days were mapped into the 160 stratified conditions, the result would be that the majority of the cells in the grid would be empty, and there would be many singletons. So in an effort to reduce the analysis to something more practical than pure enumeration, the analyst can frequently find themselves creating a trap in which the level of effort is roughly the same as pure enumeration but actually a worse characterization of overall conditions (if all conditions are considered of equal weight). Data-driven statistical methods. The overarching goal of these techniques is to find subsets of days (or peak periods) and to find a practical small set (for simulation studies, generally fewer than 20 operational conditions) of representative operational conditions. Further, a rule of thumb with respect to statistical methods like cluster analysis is that the resulting subgroups that characterize operational systems well lies somewhere around the square root of 50% of the number of days (or peak periods); for our 200-day analysis, this translates into Square Root (SQRT) of (50% x 200) = 10 most frequent conditions. This reduces the complexity of an annual analysis by 95% compared to a purely enumerative or stratifying approach and is more representative because the attributes characterizing each day are not wholly independent—in fact they are highly dependent. For example, snow/ice conditions are almost never associated with high demand. The days with high demand, specific incident patterns, and non-extreme weather tend to cluster together. Likewise lower demand days, with associated incident patterns and characterizing weather also group. One can continue this thought exercise from any of the three major attributes (e.g., extreme weather is associated with lower demand and so on). The result is the same—and the power of the statistical method is that the computer algorithms essentially conduct this kind of thought process from nearly every conceivable angle before suggesting specific subgroups (and related days). Objective-focused operational conditions analyses. Note that operational conditions analysis should also be needs-driven. If the alternatives being compared only differ under specific weather conditions (e.g., icy/snow conditions) then clustering on a subset of days that have this attribute is a good way to focus project resources. One key is to use the full data set to characterize how frequent these conditions occur annually (e.g., these days represent 10% of all weekdays in the year) before using an analytic technique to characterize snowy/icy operational conditions in greater detail. A recent study (Chicago AMS Testbed report (to be completed)) used this technique specifically for weather-related operational interventions. Reliability analyses. Capturing various operational conditions can also help a data analyst conduct reliability analysis. Even without running cluster analysis, the analyst can still perform reliability analyses using observed data. Based on the system profile, a data analyst can identify operational conditions by simply filtering the data, such as low demand days without incidents, or the days with both incident and weather impacts. For example, Federal Highway Administration (FHWA) developed an approach to measure travel time reliability. (Travel Time Reliability Measures.) Transportation Research Board (TRB) Second Strategic Highway Research Program (SHRP2) also initiated several research related projects to incorporate reliability performance measures into the operation and planning process. (Strategic Highway Research Program 2 (SHRP 2) Reliability Research Reports.) Rare events. In some cases, an operational condition may only occur every few years or is unobserved, such as natural disasters (e.g., hurricane) or other special cases/events (e.g., Olympics). It is impossible to characterize the operational condition given the fact that data is not available. A data analyst needs to figure out a way to best represent the condition, such as finding the maximum delay of the system, screening the data for the day that is close to it, or using data from other locations with the similar situation. Moving to Module 4: Operational Conditions SummaryIn order to move forward towards a more complete analytical design, the analyst that assembles, assesses, and analyzes data to characterize operational conditions should capture the main elements of that effort in an Operational Conditions Summary. The simple template offered in Table 5 can be tailored for the specific type of analysis to be performed. Note that the Summary is not used to explain how the analysis was conducted; it shows the results of the effort that will impact the proposed analysis, namely the identified operational conditions. The periods/days identifies the full set of days or peak periods used in the analysis (under the header "All") and the number of days associated with each operational condition. In each of the operational conditions columns, the percent of annual occurrence or frequency is expressed as a percentage of the total number of days analyzed. The operational conditions characterization describes the nature of the operational condition providing context for the analyst. Characterizing some operational conditions will be clear while the underlying root cause may be difficult to discern for others. In this sample, the condition associated with "bottleneck trouble" was a set of conditions under which one or more of the two recurrent bottlenecks had poor performance over the period, although the underlying cause was not evident from the data assembled. One conjecture is that for these days, local visibility (glare) issues or road surface conditions may have played a role in impeding bottleneck operations. The representative day identifies a single day from the operational condition to be used within the analysis plan. This day is generally near the center of the cluster but should also have good time-dynamic data for the key performance and calibration measures. The attributes table shows the set of attributes that the algorithmic approach used to differentiate the operational conditions. The value of each attribute is shown, as well as the aggregate annual average for comparison. Summarizing the operational conditions is a critical resource in order to complete the analysis plan. The number of operational conditions is critical to understanding the calibration and analytical requirements for the overall effort. Identifying the representative day in each operational condition is critical to providing the detailed time-variant data required for calibration. Note that the summary alone is not enough to conduct the analysis. Detailed time-variant data for each of the key performance measures must be organized and made available for calibration for each of the identified representative days. You may need the Adobe® Reader® to view the PDFs on this page. |
|
United States Department of Transportation - Federal Highway Administration |
||