Weather Applications and Products Enabled Through Vehicle Infrastructure Integration (VII)
9. Extracting Intelligent Information From VII Data
DATA FUSION, DATA ASSIMILATION, AND EXPERT SYSTEMS
Meteorologists attempt to utilize all of the relevant information at their disposal to analyze current atmospheric conditions and formulate predictions of the weather. Over time, each develops a wealth of experience and knowledge regarding the strengths and weaknesses of various datasets and products. Moreover, they use well-developed subjective techniques and rules of thumb to combine information from disparate sources to achieve the optimum analysis or forecast. Forecasters who are regarded as experts in the field have improved their accuracy and skill over time by learning from their experiences.
In recent years, forecasters have been presented with a plethora of datasets and products. Although each of these resources has the potential to contribute vital information about the current and future state of the atmosphere, the process of examining and analyzing each of these components can be overwhelming, and in many cases, a forecaster must limit him or herself to a core group of products. The meteorological community has recognized this fact, and has made an effort to utilize intelligent system approaches to perform data analysis, data integration, product construction, and verification. The ultimate goal of an intelligent or "expert" system is to perform at the level of a human expert by leveraging knowledge and experience that has been gained over time.
9.1 Data Fusion
VII will provide new datasets that can contribute to expert systems, but at the same time, it will be a complex dataset that will have very distinctive characteristics. It is unlikely that VII data will be able to be used alone to make determinations about weather or road conditions; thus, there will likely be a need to explore techniques that integrate VII data with other weather-related datasets. The use of expert systems may be one method by which VII data can be combined with other datasets.
There are several types of experts systems: rule-based, fuzzy logic, frame-based, neural networks, and hybrids (22). Much of the progress associated with advanced weather system design has been achieved by implementing fuzzy logic (continuous set theory) as the core mathematical foundation; however, the final system design is typically a combination of intelligent technologies (i.e. a hybrid expert system).
Classic Boolean logic, which is two-valued, draws upon well-defined, concrete categories (sets) to solve problems and answer questions. For example, consider the following statement:
"It is hot outside"
Boolean logic can only evaluate this statement in one of two ways: true or false. This is illustrated in Figure 9.1, with the red line (crisp set) demonstrating that the degree of membership (degree of truth) can only be 0 or 1. Note that because Boolean logic is two-valued, it cannot be used to characterize ambiguous concepts or solve nebulous problems. In contrast, the strength of fuzzy logic is the idea of multi-valued degrees of membership (22). The fuzzy set displayed in Figure 9.1 shows that the degree of membership can range from 0 to 1 (green line), which alleviates the need to set thresholds too early in the process (i.e. using 80oF as a breakpoint between not hot and hot). As a result, an expert system can be designed to problem solve in the same manner as a human does, by combining heterogeneous datasets with differing levels of uncertainty to answer a question. This concept could be extremely powerful in terms of fusing VII data with ancillary datasets to construct road weather products.
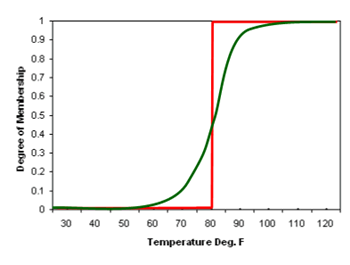
FIGURE 9.1. Crisp (red line) and fuzzy (green line) sets of "hot outside".
The process of diagnosing and forecasting weather-related hazards for all modes of transportation is beset with numerous challenges, with each mode offering its own set of unique issues. The lack of consistently accurate road weather hazard products is the result of several factors, some of which are noted below.
- Knowing the current and future state of weather and road conditions is dependent in part on having an extensive network of near surface observations. Many weather-related applications that target surface weather rely upon the national ASOS/AWOS network of observations. These observations are not generally located along roadways, and some of the data produced by these stations are not representative of near surface conditions (i.e. within a few feet of the surface). The deployment of road weather information systems (RWIS) has helped this issue, but the number of RWIS varies significantly from state to state, and the quality of data produced by some RWIS remains questionable due to the lack of uniform sensor maintenance and siting practices.
- A thorough understanding of the physical mechanisms that are responsible for road weather hazards is currently lacking. For instance, one atmospheric phenomenon that has been responsible for numerous fatal multi-car pileups along the nation's roadways is fog. Although the conditions commonly associated with fog have been identified, a substantial amount of research is still necessary to understand fully the physical processes associated with the formation, maintenance and dissipation of fog.
- Although there have been noteworthy advancements in the area of atmospheric numerical modeling, the ability of models to accurately resolve clouds and precipitation is limited. These elements are extremely important for highway safety and mobility. Dedicated research focused on these aspects of numerical modeling is currently being conducted, but it may be some years before models are able to consistently provide accurate, timely analyses and forecasts of precipitation intensity, location, and type.
These deficiencies reinforce the need to utilize data fusion techniques, such as those used in some expert systems, to integrate VII datasets with supplemental data to develop road weather products. Such techniques and systems are designed to take advantage of the strengths of various inputs (e.g. VII data, ASOS observations, model data, etc.) while minimizing the impact of their weaknesses. Moreover, these techniques can facilitate the fusing of large quantities of data to produce output that can be easily interpreted by end users or readily incorporated into other applications.
Section 6 illustrated the fact that weather-related vehicle data is highly correlated with supplementary data such as radar data and surface observations. Figure 9.2 shows a schematic of a data fusion product that includes VII data along with ancillary data. This product uses observations of wiper state, remotely sensed data, and supplemental surface observations (e.g. NWS ASOS stations) to diagnosis the location of heavy precipitation and its relation to major roadways. Each of the selected datasets is considered to have the ability to contribute some level of intelligence regarding the location of heavy precipitation in the region. For example, heavy precipitation is likely to be well correlated with VII wiper state reports of "high"; therefore, numerous reports of high wiper settings within a distinct area will increase the level of confidence that heavy precipitation is occurring in that area. Each dataset is mapped to an interest field using a fuzzy logic function. These functions are typically defined by human experts that have extensive experience with each dataset. Each of the resulting interest fields are normalized from 0 to 1, which simplifies the process of combining disparate data. Weights are applied to each of the normalized interest fields prior to combining the data. In some systems, these weights remain static, and in others, the weights can change each time the system executes.
Figure 9.2 illustrates a dynamic system where the weights are automatically adjusted based on validation of the inputs. In either case, the weights must be initially determined by a human expert. In this example algorithm, it is likely that radar data would initially receive the highest weight given that radar data generally do a good job identifying locations of heavy precipitation. In addition, radar data have been used for some time, and a considerable knowledge base has been built concerning the strengths and weaknesses of the data. As experience with VII data grows, the potential contribution of VII data in road weather applications will become clearer. In the heavy precipitation scenario, it is very plausible that wiper state data would be given the second highest weighting in the system since there is a direct relationship between heavy precipitation and wiper state. The final product shows which major roadways in the region are most impacted by heavy precipitation at the time the algorithm is run. This product uses a red, yellow, green color sequence to denote roads that are heavily impacted, moderately impacted, and unaffected, respectively.
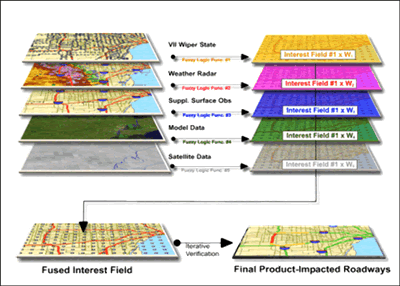
FIGURE 9.2. Schematic of a "heavy precipitation" fuzzy logic algorithm that utilizes VII data, radar data, model data, satellite data, and supplemental surface observations.
The example displayed in Figure 9.3 illustrates the use of VII data in the diagnosis of slippery pavement conditions. This product can be used in decision support systems that help to provide guidance for winter maintenance operations. Maintenance managers and crews can quickly identify the locations where they should focus additional resources. ABS information is the most critical element of the algorithm, as clusters of positive ABS events may be able to aid in pinpointing roadway segments that require the attention of maintenance crews. Note that more than one VII parameter could be used in the same application. In this case, vehicle speeds derived from VII data could be useful in determining areas where traffic speeds have been substantially degraded due to hazardous road conditions. Multiple ABS events may be correlated with decreases in average vehicle speed along a segment of roadway. Much like the previous example, several ABS events within a well-defined area would be required before the algorithm indicates slippery conditions. Additionally, slippery conditions inferred by ABS events would need to be supported by other data inputs. Since there is minimal experience using VII data, a considerable amount of research will be necessary to define the best practices for utilizing these data.
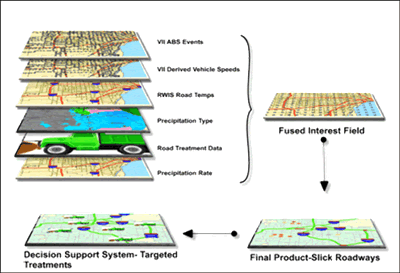
FIGURE 9.3. Representation of a data fusion algorithm for slick roadways.
9.2 Assimilating VII Data
VII-enabled data not only could be used directly as input into expert systems, but they could also contribute to other system inputs. Many expert systems rely on numerical model nowcasts and forecasts to produce optimized diagnoses and predictions of the atmosphere. As with other system inputs, an expert system attempts to maximize its performance by weighting model inputs based on their past performance. A numerical model's capacity to correctly predict the future state of the atmosphere is heavily reliant on accurately assessing the initial conditions. Numerical models use assimilation techniques to gather and process observations to evaluate the atmospheric conditions at t=0; however, the level of accuracy is related to the assimilation technique and the availability of observations.
Assimilating weather-related data enabled by VII into numerical models would improve model analyses and forecasts. A High-Resolution Land Data Assimilation System (HRLDAS) has been designed to simulate fine-scale soil moisture and temperature fields, surface sensible and latent heat fluxes, surface runoff, and water table recharge for use in mesoscale models (23). VII would provide additional information about two of the most important forcing conditions used in HRLDAS: precipitation and solar radiation. In turn, improved output from HRLDAS would enhance road weather analyses and forecasts produced by mesoscale models.
Another data assimilation technique that has been shown to improve mesoscale (10s to 100s of km scales) and miso-scale (40 m to 4 km scales) model forecasts is the Real-Time Four Dimensional Data Assimilation (RTFDDA) system developed by NCAR and the Army Test and Evaluation Command (ATEC). The system incorporates real-time observations into a continually running data assimilation system. Each real-time observation is weighted based upon the time and location of the observation (24). Currently, the RTFDDA ingests data for a number of sources, but surface observations are limited to hourly reports and regional mesonets. Again, VII would supply additional high-resolution data to assimilation systems such as the RTFDDA system, facilitating improvements in road weather products.
Finally, an ensemble Kalman filter assimilation system with one dimensional column domains has been used successfully to generate a virtual boundary layer profiler network from surface observations alone (25). The inputs to this system include surface observations of temperature, winds and water vapor. Although vehicles are presently only capable of supplying temperature observations to this system, future automotive advancements may result in the availability of atmospheric moisture and wind information (speed and direction), which in turn, would provide a voluminous dataset for this technique.
Key Points:
It is unlikely that VII-enabled weather-related data elements will be able to stand alone as truth. The most effective method of exploiting VII weather and road condition data will be to combine the data with conventional datasets such as nearby stationary surface observations or remotely sensed data.
Data fusion has been used by the weather community for numerous years to extract and combine information from disparate datasets. These techniques, which attempt to take advantage of a dataset's strengths while minimizing the impact of its weaknesses, have been used in many expert weather systems. Weather applications and products that attempt to use VII-enabled data should take advantage of data fusion techniques.
The accuracy of weather forecasts produced by numerical models is highly dependent in part upon the model's ability to correctly assess the initial state of the atmosphere. Such models use data assimilation techniques to gather information concerning the current conditions; however, the amount of available data, especially near surface, is limited. VII will provide data that can help to fill existing gaps, which will result in improved weather forecasts.